
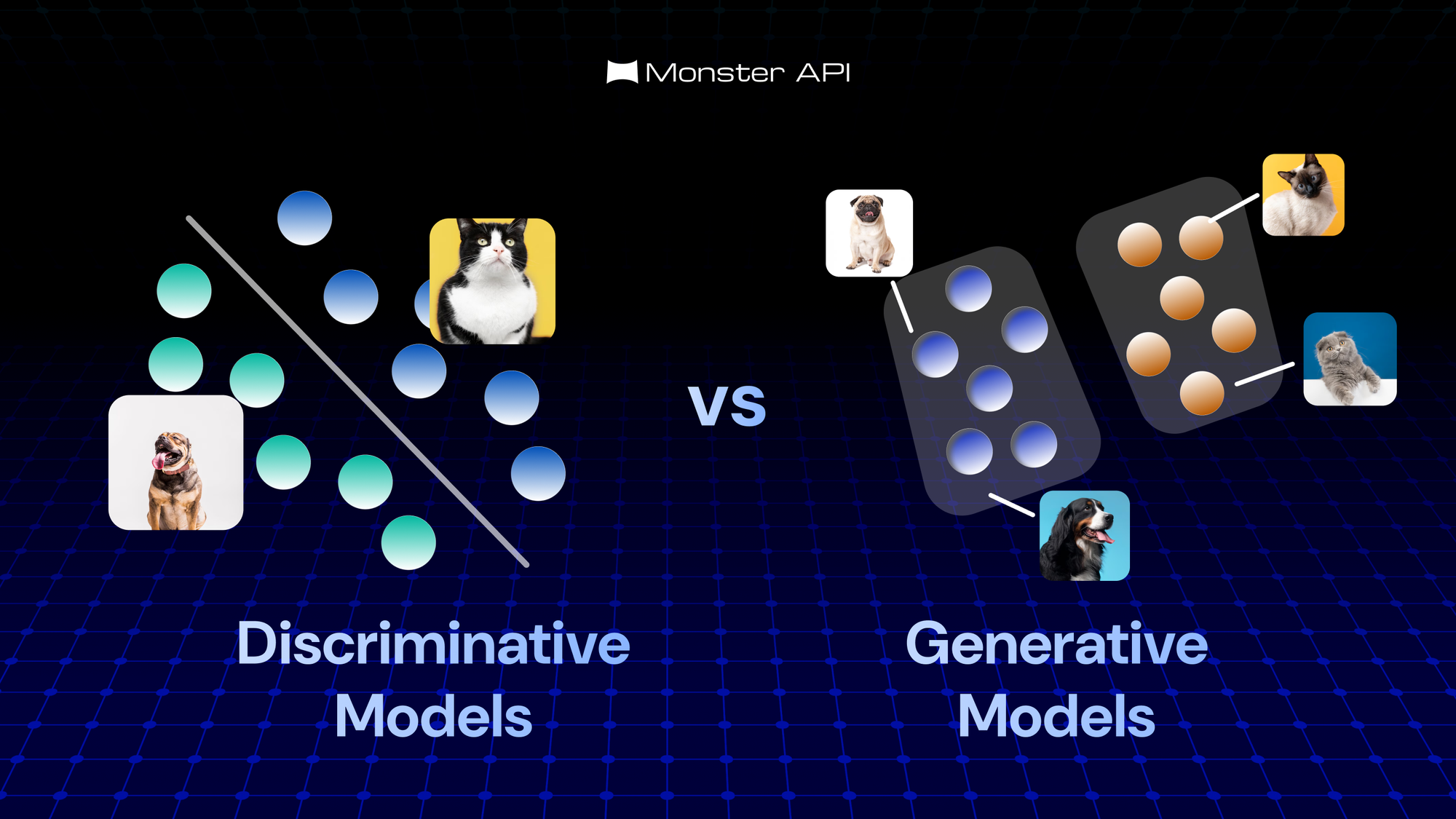
Discriminative vs Generative Models
Discriminative and generative models approach prediction tasks differently—one focuses on decision boundaries, the other on data generation. This blog breaks down their mathematical foundations, practical use cases, and how to choose the right model for your ML tasks.

Introduction
In the field of machine learning, models are broadly categorized into two families based on how they approach prediction tasks: Discriminative models and Generative models. Although both types aim to make predictions, the way they interpret input data, model relationships, and handle uncertainty is fundamentally different.
Understanding this distinction is crucial for building effective machine learning systems. Choosing the right type of model influences not only prediction accuracy, but also the amount of training data required, the types of problems that can be addressed, and the model’s ability to generalize or generate new data.
In this blog, we will explore discriminative and generative models at a technical level, breaking down how they differ mathematically, conceptually, and practically.
What are Discriminative Models?
Discriminative models are a family of machine learning models that focus on drawing boundaries between different categories of data. Their goal is simple: Given an input, decide which output label it most likely belongs to.
They do not attempt to understand how the data was generated or modeled internally. Instead, they directly learn the relationship between input features and output labels — mapping inputs to outputs in the most accurate way possible.
In short, discriminative models are experts in classification and prediction: they make the best guess based on observed patterns.
How Discriminative Models Work
Discriminative models operate by learning the conditional probability P(Y∣X) where:
- X represents the input features (e.g., email text, image pixels)
- Y represents the output labels (e.g., spam or not-spam, cat or dog).
This means that for every new input, the model estimates the probability of each possible label and chooses the one with the highest probability. The training process adjusts the model’s internal parameters to make these conditional predictions as accurate as possible on the training data.
Discriminative models focus purely on separating different outcomes based on the observed features — without trying to model the input space itself.
Examples of Discriminative Models
- Logistic Regression: Logistic Regression is one of the simplest yet powerful discriminative models. It predicts the probability that a given input belongs to a particular class by applying a logistic (sigmoid) function. This function ensures that the output is a value between 0 and 1, which can be interpreted as a probability. Logistic Regression draws a linear decision boundary between classes.
- Support Vector Machines (SVMs): SVMs aim to find the best possible boundary (hyperplane) that separates different classes of data. The model chooses the hyperplane that maximizes the distance (margin) between the classes, which improves the model's ability to generalize to unseen data.
- Decision Trees: Decision Trees split the input space into smaller regions by asking a series of "if-then" questions based on feature values. Each path through the tree corresponds to a sequence of decisions leading to a final class prediction.
- Random Forests: A Random Forest is an ensemble of many Decision Trees working together. Each tree gives a classification, and the Random Forest chooses the most popular class across all trees, improving robustness and reducing overfitting.
- Linear Regression (for continuous outputs):Although typically associated with predicting real-valued outputs, Linear Regression still fits the discriminative modeling approach. It learns a direct relationship between input features and a continuous output by fitting the best possible straight line (or hyperplane) through the data.
Quick Practical Example
Consider a spam email classifier.
A discriminative model learns specific patterns in email text that indicate whether an email is spam or not. For example, the frequent appearance of words like "winner", "free", or "urgent" might push the model towards predicting "spam."The model does not try to generate what a typical spam email looks like — it simply focuses on making the correct classification based on observable patterns.
Limitations of Discriminative Models
Imbalanced Datasets: Discriminative models tend to be biased toward majority classes when trained on imbalanced data. They optimize for overall accuracy, potentially sacrificing performance on minority classes.May produce high accuracy metrics while completely failing on underrepresented but critical case.
Limited Uncertainty Quantification: Often provide point estimates without reliable confidence measures. Calibration of probabilities can be poor, especially in deep discriminative models. Struggle to express "I don't know" when faced with out-of-distribution inputs.
Data Efficiency Issues: Require substantial labeled data to perform well. Performance degrades sharply when training data is limited. Cannot easily leverage unlabeled data without additional techniques.
Feature Engineering Dependency: Performance heavily depends on the quality of input features. May require extensive feature engineering in domains where raw features aren't directly predictive. Less effective at discovering useful latent representations automatically.
Distributional Shift Vulnerability: Perform poorly when test data distribution differs from training data. No inherent mechanism to detect when inputs come from a different distribution. May make confident but incorrect predictions on out-of-distribution samples.
What are Generative Models?
Generative models are machine learning models designed to understand the underlying structure of data. Rather than focusing only on predicting labels, these models aim to capture how data points are created, how different features interact, and what typical examples of each category look like internally.
Once trained, a generative model can do more than classify — it can create new data samples that resemble the original data.This ability comes from modeling the probability distribution of the data itself.
In short, a generative model is trained not only to recognize but also to imagine.
How Generative Models Work
At the core, generative models learn the joint probability distribution P(X,Y) where:
Y is the output label or category (such as "dog," "approved," or "positive sentiment").
X is the input data (such as an image, a transaction record, or a sentence),
To build this understanding, they typically decompose the problem into two parts:
Model P(X∣Y): How the data looks for each specific class.
Model P(Y): How frequently each class occurs in the real world.
This approach allows generative models to simulate new examples.For instance, after learning the common characteristics of a "positive review," a model could generate a completely new positive review that fits the learned distribution.
When needed for classification tasks, generative models can apply Bayes' theorem to invert the relationship and predict P(Y∣X), even though their main strength lies in modeling how the data is generated.
Examples of Generative Models
- Naive Bayes Classifier: Naive Bayes assumes that features are conditionally independent given the class label. It estimates P(X∣Y) for each feature and combines them to predict the most likely class. Despite its simplicity, it works remarkably well in tasks like spam detection and text classification.
- Gaussian Mixture Models (GMMs): GMMs assume that the data is generated from a mixture of several Gaussian distributions. They learn the parameters (mean, variance) of each Gaussian component and can model complex data distributions by combining them.
- Linear Discriminant Analysis (LDA):LDA is both a classification and dimensionality reduction technique. It models the distribution of each class and projects the data in a way that maximizes class separability, based on the assumption of normally distributed classes with equal covariance matrices.
- Variational Autoencoders (VAEs): VAEs are deep generative models that learn a compressed representation of the data (latent space) and can generate new data points by sampling from this learned space.
- Generative Adversarial Networks (GANs):GANs consist of two networks — a generator and a discriminator — that compete against each other. The generator learns to create new samples that are so realistic that the discriminator struggles to distinguish them from real data.
Quick Practical Example
Suppose you are building a system to monitor machinery in a manufacturing plant.
A generative model could learn the normal operating behaviour of the machines — the typical sounds, vibrations, temperatures, and operating cycles — across thousands of hours of data.
Later, if the system detects a behaviour pattern that deviates sharply from what the model expects, it could flag it as a potential fault, even before a human notices anything unusual. This early fault detection capability comes not from labeling "normal" vs "faulty" explicitly, but from the model’s deep understanding of what "normal" looks like.
This is the power of generative modeling — it doesn't just detect problems you already know about; it can sense anomalies because it understands the "normal world" deeply.
Limitations of Generative Models
Unrealistic Sample Generation: May generate implausible samples when modeling complex, high-dimensional distributions. Can produce artifacts, blurry results, or physically impossible outputs. Often struggle with coherence in long-sequence generation (text, music, video)
Mode Collapse: Tendency to capture only a subset of the true data distribution. May repeatedly generate similar samples while missing diversity in the real data.Particularly problematic in GANs and some VAE implementations.
Training Instability: Many generative models (especially GANs) have notoriously difficult training dynamics. Require careful hyperparameter tuning and architecture design. May never converge to a stable solution in complex domains.
Computational Intensity: Typically require significantly more computational resources than discriminative counterparts. Longer training times and higher memory requirements. Inference can be slow, especially for autoregressive and diffusion models.
Evaluation Challenges: Difficult to objectively measure the quality of generated samples. Metrics like likelihood can be misleading (models can assign high likelihood to poor samples). Human evaluation is subjective and doesn't scale.
Curse of Dimensionality: Performance degrades rapidly as the dimensionality of data increases. Estimating joint distributions becomes exponentially harder in high dimensions. May require restrictive independence assumptions to remain tractable.
Privacy and Memorization Concerns: Risk of memorizing training examples rather than generalizing. May inadvertently reproduce sensitive information from training data
Hybrid Models
Hybrid models in machine learning combine the capabilities of both discriminative and generative approaches within a single architecture or training strategy. Rather than relying purely on one modeling philosophy, hybrid models are explicitly designed to predict outputs accurately and understand or recreate the underlying structure of data at the same time.
This combination allows models to perform well in classification, generation, anomaly detection, semi-supervised learning, and other complex tasks where pure discriminative or pure generative approaches may struggle individually.
Types of Hybrid Approaches
1. Discriminative Learning on Generative Representations
In this approach, a generative model is trained to learn meaningful representations of the data, and a discriminative classifier is trained separately on these representations. Instead of using raw features, the classifier leverages the structured information captured by the generative model, improving performance, especially with limited labelled data.
Example: A Variational Autoencoder (VAE) is trained to compress images into latent vectors. Later, a classifier is trained on these latent vectors to predict image labels, benefiting from the VAE’s learned structure.
2. Generative Modeling Guided by Discriminative Objectives
Here, a generative model is encouraged to create realistic data while simultaneously optimizing a discriminative task, such as classification. The model’s objective combines generation quality and class separation, making the generated data not only realistic but also organized for downstream tasks.
Example: In Semi-Supervised GANs, the discriminator is trained both to distinguish real vs fake images and to classify real images into categories, guiding the generator to produce classifiable samples.
3. Joint Estimation of P(X,Y) and P(Y∣X)
Some models are designed to model both the full data distribution P(X,Y) and the conditional distribution for prediction P(Y∣X) simultaneously. This dual modelling helps the system learn data structure and decision boundaries together, improving generalization with fewer labelled examples.
Example: Energy-Based Models (EBMs) minimize an energy function over input-label pairs, learning to model both how data is distributed and how to predict labels efficiently within a single framework.
Choosing the Right Model: Discriminative or Generative?
Selecting the right type of model is not just a theoretical decision — it fundamentally shapes how a machine learning system performs in real-world conditions. The choice depends on the task objective, the nature of available data, and the demands of the problem.
Each modeling philosophy offers distinct strengths, and understanding when to favor one over the other is critical for building effective AI systems.
1. What Is the Primary Goal of the System?
- If your goal is purely predictive — maximizing classification or regression accuracy — a discriminative model is generally more appropriate.
- If your goal involves creating new data, understanding hidden structures, or detecting deviations from normal patterns, a generative model may be necessary.
Example: A document classification system (spam vs non-spam) typically uses discriminative models. A synthetic data generation tool for training autonomous vehicles would rely on generative models.
2. What Type of Data Is Available?
- If you have abundant labeled data that covers most of the scenarios your system will encounter, discriminative models can directly learn effective decision boundaries.
- If labeled data is scarce, or if you expect new, unseen variations in the data, generative models — which model the underlying distribution — may generalize better.
Example: A customer churn prediction task with years of labeled history fits discriminative modeling. An anomaly detection system for rare network intrusions benefits from generative modeling.
3. How Much Complexity Can the System Tolerate?
- Discriminative models are often simpler to train and deploy, with faster convergence and easier interpretability.
- Generative models generally require more complex architectures, longer training times, and careful evaluation, but offer greater flexibility.
Example: In edge devices with limited compute (e.g., on-device fraud detection), discriminative models are preferable. In research-grade systems where capturing subtle data structure matters (e.g., biomedical imaging), generative models are often worth the investment.
4. Is Robustness to Unseen Data Critical?
- When the system must be robust to novel, unexpected inputs (such as zero-shot cases or subtle distribution shifts), generative models have an edge because they model the full data space.
- If the application domain is well-bounded and structured, discriminative models can deliver high performance without needing generative flexibility.
Example: A speech-to-text system designed for a controlled set of accents may use discriminative modeling. A malware detection system that must recognize new, unseen attack patterns may benefit from a generative approach.
Conclusion
The distinction between discriminative and generative models runs deeper than technical definitions — it reflects two fundamentally different ways of thinking about prediction, learning, and uncertainty. In practical machine learning, understanding these approaches is not about choosing sides, but about selecting the right tools for the right tasks. As real-world applications grow more complex, blending discriminative precision with generative understanding will continue to define the evolution of intelligent systems.